
If you are wondering whether you can exploit a system which doesn't have any software vulnerabilities just by using hardwares or if you find using hardware to extract the private encryption keys from a victim program running GnuPG interesting then hold on. This is going to be a series of posts related to Hardware security and we start off with a simple but effective low noise side channel attack called FLUSH+RELOAD which is capable of exfiltrating sensitive information with high fidelity. FLUSH+RELOAD is a side channel attack technique that exploits the weakness in the Intel X86 processors, Page sharing exposes process to information leaks. FLUSH+RELOAD atack targets the Last-Level cache (LLC) ( i.e. L3 cache on processors with three cache levels).
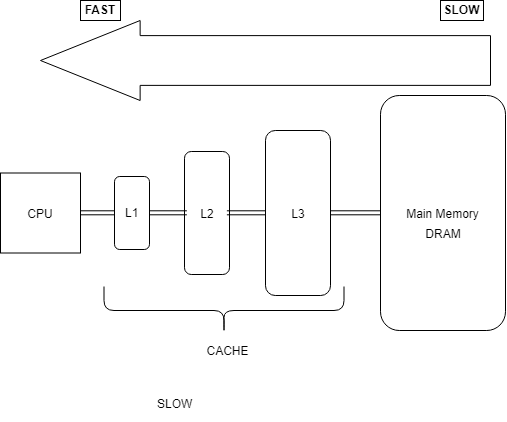
Lets first look at the basics: Why do we need Cache when we already have DRAM's ranging from few to 2 Gigabytes?
As a computer system is built using components from different suppliers, there are no standards on the speed and transfer rates of these components.One of the main reason why we use Cache is because of Latency, a larger resource like DRAM incurs a significant latency for access – e.g. it can take hundreds of clock cycles for a modern 4 GHz processor to reach DRAM, and since most of the data are likely to be used again, Hardware implements cache as a block of memory for temporary storage of data, which can be accessed faster than DRAM.
For example, Lets say we have a code that does this,
for( int i=0 ;i<100 ;i++){ int Temp = array[0]; }
As we can see , it is not efficient to assign the same value array[0] to Temp 100 times, the compiler realises it and optimizes it , but lets say we don't have compiler optimization,
Lets say that accessing array[0] from DRAM takes 300 Cycles , If we do this over and over again for 100 times we are spending 300 x 100, but the value of array[0] has not changed inside the loop , so we are spending a lot of cycles in accessing the same data from the DRAM. But if we have caches in between the DRAM and the CPU, let's assume that we have only one layer of Cache and accessing data from Cache takes (50 cycles), then we would spend 100 Cycles for i=0 then array[0] would be in the cache and then subsequent request to array[0] would fetch the data from cache instead of the DRAM which is ( 50 * 99 Cycles ) for a total of 100 + (50 * 99) Cycles, which is better and faster than accessing the same data from the DRAM Every time. But the size of the cache has to be small, since having a larger Cache (as the same size of the DRAM would mean that accessing data from the cache is going to take longer and almost as same as 300 Cycles) , So we have a limited cache size , for example the Intel-Core-i7-5820K-Processor 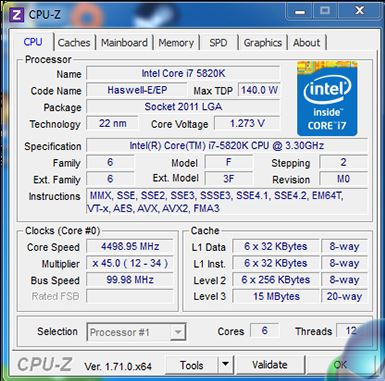
Has 15 MBytes L3 Cache and 6x256 KBytes of L2 Cache and 6x32 Bytes of L1 (Data/Instruction ) Cache.
So the moral is that , if the data is in the Cache we can access it faster.And when does the data appear in the cache ? Some one has to access that particular data first. So say if both the victim and the attacker are using the same system, can the attacker use this memory access timing as a side channel to guess the data that victim is acccessing ?
Your guess is right. We can. Now lets look at how we can achieve this with Flush+Reload.
As the name suggests we are going to Flush the data that we want to monitor from the cache and then Reload the same data after some time and analyze the timing and see if the victim has accessed it. If it takes less time then the victim has accessed it as it is being read from the ram.
To reload the data we can just read the data ex: int Temp = array[0]
But to Flush the data from the Cache we use the processor's cflush instruction to evict the monitored memory location from the cache ,
say we want to evict array[0] from the cache we can use inline assembly in c to do this
__asm__ volatile("clflush (%0)" :: "r" (array));
This would flush array from all the caches.
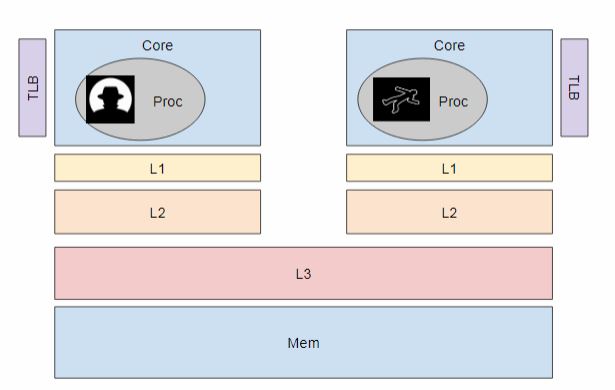
The Cache L1 and L2 are private to each cores but the L3 cache are shared amongst the cores, and in Intel processors L1 cache is inclusive of L3 cache(at least till i9), i.e. if the data is in L1 it will also be present in the L3 cache , so if we flush the cache from the attacker's core then it would flush the address from L3 cache which is shared by the victim core, which would in turn flush the address in L1 cache from the victims core, so the next time the victim tries to access array[0] it has to fetch the value from the DRAM.
If both the attacker and the victim has access to Crypto.so ,then the attacker can Flush Crypto.so, there by flushing it from L3 cache as well and in turn flusing it from the L1 cache of the victim.
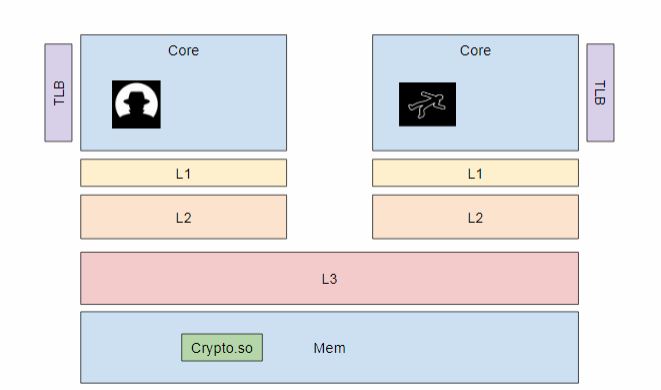
Now the attacker makes the victim use the crypto.so say for ex, the attacker sends an RPC call with some data and then Vicitm would call functions in Crypto.so with the data which we control.
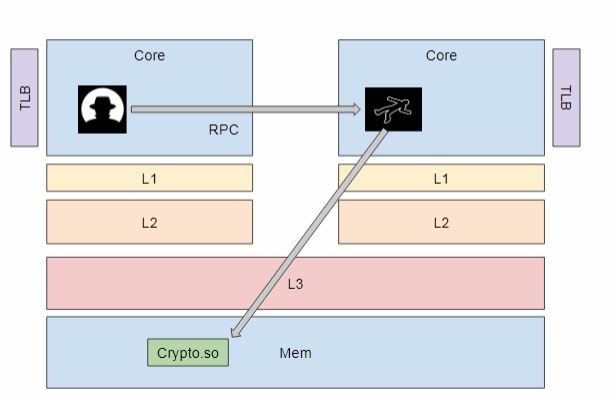
This will load the function into the L3 cache and then into L1 cache of the victims core.Now when the Attacker accesses the same function after a given time, instead of fetching it from DRAM , it would fetch it from the Cache and the attacker can use this timing differnce to know that the particular function was used by the victim.
If the timing is 50 cycles then the attacker can conclude that the victim has called the said function.
If the timing is 300 cycles then he can conclude that the vicitm hasn't called the said function.
Assumption:
We assume we can control and time when the victim executes , so it is going to be a little hard to come up with a POC for that for now , but now to show how it works compile and run the following code with gcc/g++
#include <iostream>
#include <stdio.h>
using namespace std ;
static inline uint64_t rdtsc() {
uint64_t a = 0, d = 0;
asm volatile("mfence");
asm volatile("rdtscp" : "=a"(a), "=d"(d) :: "rcx");
a = (d << 32) | a;
asm volatile("mfence");
return a;
}
int main(){
int Timeme = 100 ;
uint64_t start = 0 , end = 0 ;
__asm__ volatile("clflush (%0)" : : "r" ((volatile void *)&Timeme) : "memory"); // Flush the address from the cache
start = rdtsc();
volatile int temp = Timeme; // Read the data from the RAM ( Also brings it to the cache)
end = rdtsc();
cout << "Time taken without Caching "<< end-start <<endl;
start = rdtsc();
volatile int temp_cache = Timeme; // Timeme now already resides in cache
end = rdtsc();
cout << "Time taken with Caching "<< end-start <<endl;
return 0 ;
}
and the output is
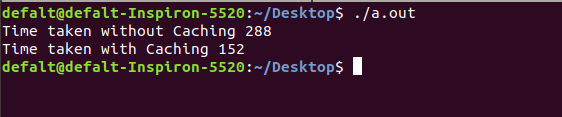
So from the output we can see that without caching it takes 288 Cycles where as in case of cached data it takes only 152 cycles.
If you are interested in learning more about Flush +Reload , then Check out the paper by Yuval YaromFLUSH+RELOAD: a High Resolution, Low Noise,
L3 Cache Side-Channel Attack which uses Flush+reload to extract the private encryption keys from a victim program running GnuPG 1.4.13.
REFERENCE
https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-yarom.pdf